- National Science Foundation of Sri Lanka Grant No. RG/2012/CSIT/01 (2012).
- National Research Council of Sri Lanka Grant No. 12-018 (2012).
- The University of Moratuwa, Senate Reaserch Commitee Grant No. SRC/LT/2016/04 (2016).
- Accelerating Higher Education Expansion and Development (AHEAD) Operation of the Ministry of Higher Education, Sri Lanka funded by the World Bank.
Projects
Digital Histopathology
These works advance AI-driven cancer pathology by addressing two key challenges: multimodal data integration and limited annotations. The SENCA-st framework introduces a cross-attention-based shared encoder to effectively fuse histopathology images with spatial transcriptomics, enabling precise identification of tumor heterogeneity and microenvironmental regions by capturing both structural and functional differences. Complementing this, the uncertainty-aware learning approach improves cancer subtyping by estimating model confidence and strategically selecting only the most informative samples for expert annotation, achieving state-of-the-art performance with minimal labeled data. Together, these contributions provide a scalable and efficient pathway for more accurate and data-efficient computational pathology systems.
Shanaka Liyanaarachchi, Chathurya Wijethunga, Shihab Ahamed, Akthas Absar, and Ranga Rodrigo, "SENCA-st: Integrating Spatial Transcriptomics and Histopathology with Cross Attention Shared Encoder for Region Identification in Cancer Pathology," in Proceedings of Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, , March 2026, pp. 3578--3587.
URL: https://openaccess.thecvf.com/content/WACV2026/html/Liyanaarachchi_SENCA-st_Integrating_Spatial_Transcriptomics_and_Histopathology_with_Cross_Attention_Shared_WACV_2026_paper.html
URL: https://openaccess.thecvf.com/content/WACV2026/html/Liyanaarachchi_SENCA-st_Integrating_Spatial_Transcriptomics_and_Histopathology_with_Cross_Attention_Shared_WACV_2026_paper.html
Nirhoshan Sivaroopan, Chamuditha Galappaththige, Chalani Ekanayake, Hasindri Watawana, Ranga Rodrigo, and Chamira Edussooriya, "Uncertainty Awareness Enables Efficient Labeling for Cancer Subtyping in Digital Pathology," in Proceedings of Winter Conference on Applications of Computer Vision (WACV), , 2025, pp. 589--598.
URL: https://ieeexplore.ieee.org/abstract/document/10944092
URL: https://ieeexplore.ieee.org/abstract/document/10944092
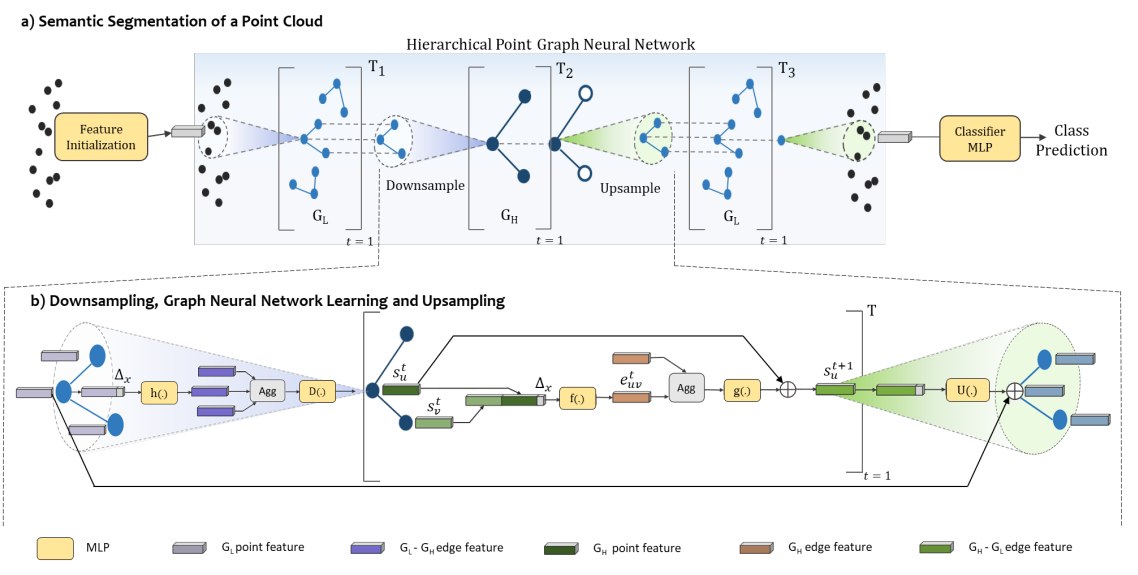
Point Cloud Processing
Point clouds, usually obtained using LiDARs, is an important perception manner commonplace in vision based autonomous navigation. One challenge of large-scale outdoor LiDAR point clouds is the high volume of points; generally millions of points per frame of observation. Object detection, and semantic segmentation important problems in the point-cloud domain.
Mohamed Afham, Isuru Dissanayake, Dinithi Dissanayake, Amaya Dharmasiri, Kanchana Thilakarathna, and Ranga Rodrigo, "CrossPoint: Self-Supervised Cross-Modal Contrastive Learning for 3D Point Cloud Understanding
," in Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, June 2022, pp. 1-10.
URL: https://openaccess.thecvf.com/content/CVPR2022/html/Afham_CrossPoint_Self-Supervised_Cross-Modal_Contrastive_Learning_for_3D_Point_Cloud_Understanding_CVPR_2022_paper.html
URL: https://openaccess.thecvf.com/content/CVPR2022/html/Afham_CrossPoint_Self-Supervised_Cross-Modal_Contrastive_Learning_for_3D_Point_Cloud_Understanding_CVPR_2022_paper.html
Arulmolivarman Thieshanthan, Amashi Niwarthana, Pamuditha Somarathne, Tharindu Wickremasinghe, and Ranga Rodrigo, "HPGNN: Using Hierarchical Graph Neural Networks for Outdoor Point Cloud Processing," in Proceedings of International Conference on Pattern Recognition, Montreal, QC, 2022, pp. 1--7.
URL: https://arxiv.org/abs/2206.02153
URL: https://arxiv.org/abs/2206.02153
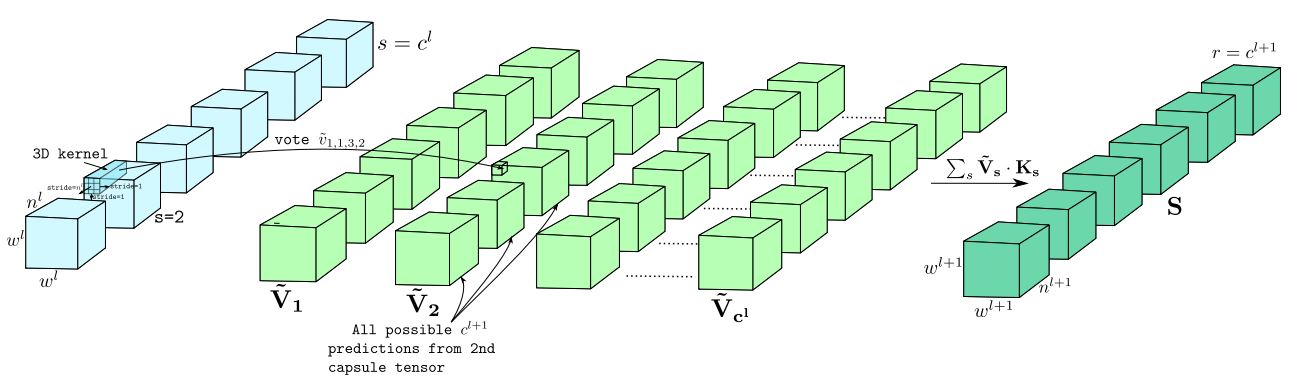
Dishanika Denipitiyage, Vinoj Jayasundara, Chamira Edussooriya, and Ranga Rodrigo, "PointCaps: Raw point cloud processing using capsule networks with Euclidean distance routing," Journal of Visual Communication and Image Representation, vol. 88, no. , pp. 103612, 2022.
URL: https://www.sciencedirect.com/science/article/abs/pii/S1047320322001365
URL: https://www.sciencedirect.com/science/article/abs/pii/S1047320322001365

Vision for Self-Driving
Computer vision is an enabler for self-driving, whether the input is camera based-video or LIDAR-based point clouds. We are working along multiple avenues to contribute to this important area.
Road marking detection and lane detection directly assist self-driving. We have introduced a novel road marking benchmark dataset for road marking detection, addressing the limitations in the existing publicly available datasets such as lack of challenging scenarios, prominence given to lane markings, unavailability of an evaluation script, lack of annotation formats and lower resolutions. In SwiftLane, we presented a simple and light-weight, end-to-end deep learning based framework, coupled with the row-wise classification formulation for fast and efficient lane detection. Both these were with the support from Creative Software under the supervision of Dr. Peshala Jayasekara.
Inspired by recent improvements in point cloud processing for autonomous navigation, we focused on using hierarchical graph neural networks for processing and feature learning over large-scale outdoor LiDAR point clouds. In point based and GNN models for semantic segmentation with our work achieves a significant improvement for GNNs on the SemanticKITTI dataset. We have also made a more fundamental contribution in using cross-modal contrastive learning approach to learn transferable 3D point cloud representations.
Oshada Jayasinghe, Damith Anhettigama, Sahan Hemachandra , Shenali Kariyawasam , Ranga Rodrigo, and Peshala Jayasekara, "SwiftLane: Towards Fast and Efficient Lane Detection," in Proceedings of International Conference on Machine Learning and Applications, , 2021, pp. 1--6.
URL: https://arxiv.org/abs/2110.11779
URL: https://arxiv.org/abs/2110.11779
Oshada Jayasinghe, Sahan Hemachandra , Damith Anhettigama, Shenali Kariyawasam , Ranga Rodrigo, and Peshala Jayasekara, "CeyMo: See More on Roads - A Novel Benchmark Dataset for Road Marking
Detection," in Proceedings of IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Wikoloa, HI, January 2022, pp. 3104--3113.
URL: https://openaccess.thecvf.com/content/WACV2022/html/Jayasinghe_CeyMo_See_More_on_Roads_-_A_Novel_Benchmark_Dataset_WACV_2022_paper.html
URL: https://openaccess.thecvf.com/content/WACV2022/html/Jayasinghe_CeyMo_See_More_on_Roads_-_A_Novel_Benchmark_Dataset_WACV_2022_paper.html

Board Games: Learning beyond Simulations
Reinforcement learning algorithms have been successfully trained for games like GO, Atari, and Chess in simulated environments. However, in cue sport-based games like Carrom, real world is unpredictable unlike in Chess and GO due to the stochastic nature of the gameplay as well as the effect of external factors such as friction combined with multiple collisions. Hence, solely training in a simulated platform for games like Billiard and Carrom, which need precise execution of a shot, would not be ideal in actual gameplay. This paper presents a real-time vision based efficient robotic system to play Carrom against a proficient human opponent. We demonstrate the challenges of adopting a reinforcement learning algorithm beyond simulations in implementing strategic gameplay for the robotic system. We currently achieve an overall shot accuracy of 70.6% by combining heuristic and reinforcement learning algorithms. Analysis of the overall results suggests the possibility of adopting a realworld training for board games which need precise mechanical actuation beyond simulations.
Naveen Karunanayake, Achintha Wijesinghe, Chameera Wijethunga, Chinthani Kumaradasa, Peshala Jayasekara, and Ranga Rodrigo, "Towards a Smart Opponent for Board Games:
Learning beyond Simulations," in Proceedings of IEEE International Conference on Systems, Man, and Cybernetics, Toronto, CA (virtual), 2020, pp. 1--8.

Context-Aware Occlusion Removal
In this work, we identify objects that do not relate to the image context as occlusions and remove them, reconstructing the space occupied coherently. We detect occlusions by considering the relation between foreground and background object classes represented by vector embeddings, and removes them through inpainting. Notice how the skier has been automatically removed.
Kumara Kahatapitiya, Dumindu Tissera, and Ranga Rodrigo, "Context-Aware Automatic Occlusion Removal," in Proceedings of IEEE International Conference on Image Processing, Taipei, Taiwan, September 2019, pp. 1--4.
URL: https://arxiv.org/abs/1905.02710
URL: https://arxiv.org/abs/1905.02710
Extensions to Capsule Networks
We extended the capsule networks taking several paths. In the TextCaps work, we adjust the instantiation parameters with random controlled noise to generate new training samples from the existing samples, with realistic augmentations which reflect actual variations that are present in human hand writing. Our results with a mere 200 training samples per class surpass existing character recognition results in MNIST and several other datasets.
In DeepCaps we developed a deep capsule network architecture which uses a novel 3D convolution based dynamic routing algorithm. Further, we propose a class-independent decoder network, which strengthens the use of reconstruction loss as a regularization term. This leads to an interesting property of the decoder, which allows us to identify and control the physical attributes of the images represented by the instantiation parameters.
Vinoj Jayasundara, Sandaru Jayasekara, Hirunima Jayasekara, Jathushan Rajasegaran, Suranga Seneviratne, and Ranga Rodrigo, "TextCaps: Handwritten Character Recognition With Very Small Datasets," in Proceedings of IEEE Winter Conference
on Applications of Computer Vision, Waikoloa, HI, January 2019, pp. 254--262.
URL: https://ieeexplore.ieee.org/abstract/document/8658735
URL: https://ieeexplore.ieee.org/abstract/document/8658735
Jathushan Rajasegaran, Vinoj Jayasundara, Sandaru Jayasekara, Hirunima Jayasekara, Suranga Seneviratne, and Ranga Rodrigo, "DeepCaps: Going Deeper with Capsule Networks," in Proceedings of IEEE CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, June 2019, pp. 1--9.
URL: https://arxiv.org/abs/1904.09546
URL: https://arxiv.org/abs/1904.09546

Deep Learning of Augmented Reality based Human Interactions for Automating a Robot Team
Getting a team of robots to achieve a relatively complex task using manual manipulation through augmented reality is interesting. However, the true potential of such an approach manifests when the system can learn from humans. We propose a system comprising a team of robots that performs a previously unseen task---a variant, to be specific---by learning from the sequences of actions taken by multiple human beings doing this task in various ways using deep learning. The training inputs can be through actual manipulation of the team of robots using an augmented-reality tablet or through a simulator. Results indicate that the system is able to fulfill the specified variant of the task more than 80% of the time, inaccuracies mainly owing to unrealistic specifications of tasks. This opens up an avenue of training a team of robots, instead of crafting a rule base.
Adhitha Dias, Hasitha Wellaboda, Yasod Rasanka, Menusha Munasinghe, Ranga Rodrigo, and Peshala Jayasekara, "Deep Learning of Augmented Reality based Human Interactions for Automating a Robot Team," in Proceedings of International Conference on Control, Automation and Robotics (ICCAR), Singapore, 2020, pp. 175--182.
URL: https://ieeexplore.ieee.org/document/9108004
URL: https://ieeexplore.ieee.org/document/9108004
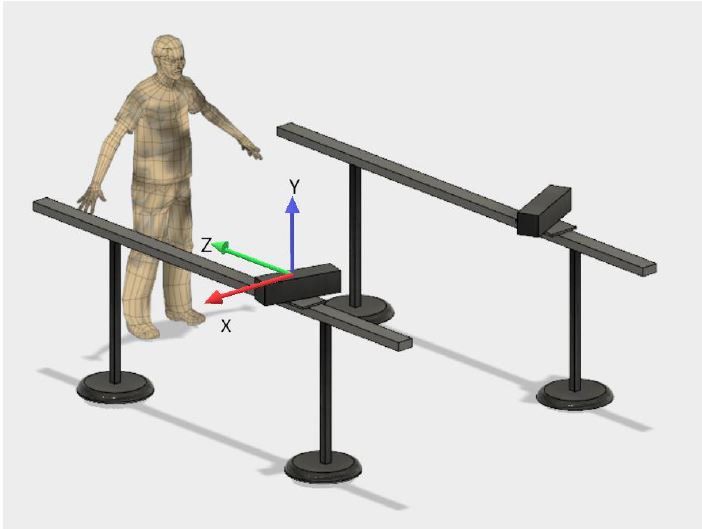
Gait Analysis
There are several systems that use one or several Kinect sensors for human gait analysis, particularly for diagnosis of patients. However, due to the limited depth sensing range of the Kinect-a sensor manufactured for video gaming-the depth measurement accuracy reduces with distance from the Kinect. In addition, self-occlusion of the subject limits the accuracy and utility of such systems. We overcome these limitations by first by using a two-Kinect gait analysis system and second by mechanically moving the Kinects in synchronization with the test subject and each other. These methods increase the practical measurement range of the Kinectbased system whilst maintaining the measurement accuracy.
Madhura Pathegama, Dileepa Marasinghe, Kanishka Wijayasekara, Ishan Karunanayake, Chamira Edussooriya, Pujitha Silva, and Ranga Rodrigo, "Moving Kinect-Based Gait Analysis with Increased Range," in Proceedings of IEEE International Conference on Systems, Man, and Cybernetics, Miyazaki, Japan, October 2018, pp. 4126--4131.
URL: https://ieeexplore.ieee.org/abstract/document/8616696
URL: https://ieeexplore.ieee.org/abstract/document/8616696
Ravindu Kumarasiri, Akila Niroshan, Zaman Lantra, Thanuja Madusanka, Chamira Edussooriya, and Ranga Rodrigo, "Gait Analysis Using RGBD Sensors," in Proceedings of International Conference on
Control, Automation, Robotics and Vision, Singapore, November 2018, pp. 460--465.
URL: https://ieeexplore.ieee.org/abstract/document/8581295
URL: https://ieeexplore.ieee.org/abstract/document/8581295
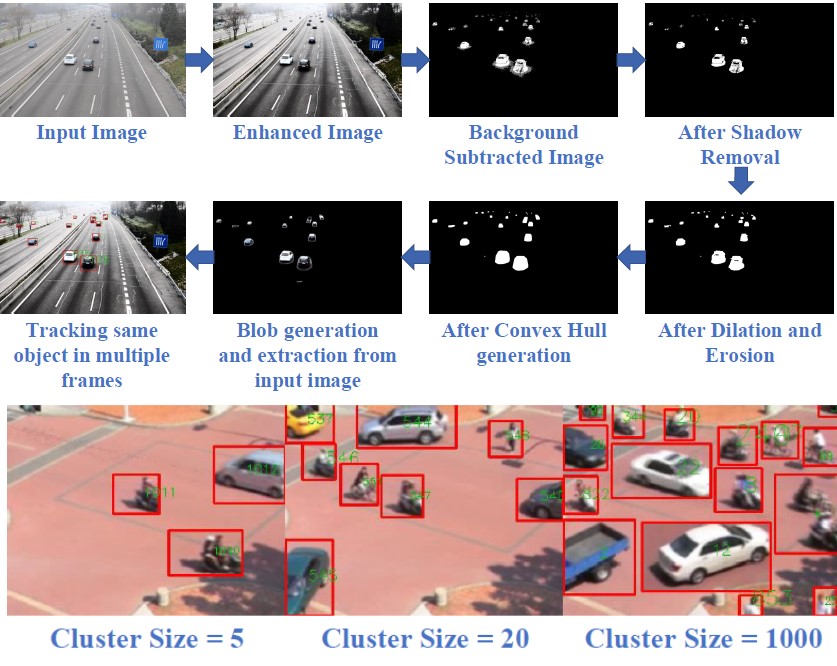
Video Synopsis
Video synopsis, summarizing a video to generate a shorter video by exploiting the spatial and temporal redundancies, is important for surveillance and archiving. Existing trajectory-based video synopsis algorithms are not able to work in real time because of the complexity due to the number of object tubes that need to be included in the complex energy minimization algorithm. We propose a real-time algorithm by using a method that incrementally stitches each frame of the synopsis by extracting object frames from the user specified number of tubes in the buffer in contrast to global energy minimization based systems. This also gives flexibility to the user to set the threshold of maximum number of objects in the synopsis video according his or her tracking ability and creates collision-free summarized videos which are visually pleasing. Experiments with six common test videos, indoors and outdoors with many moving objects, show that the proposed video synopsis algorithm produces better frame reduction rates than existing approaches in real-time.
Anton Ratnarajah, Sahani Goonetilleke, Dumindu Tissera, Balagobalan Kapilan, and Ranga Rodrigo, "Moving Object Based Collision-Free Video Synopsis," in Proceedings of IEEE International Conference on Systems, Man, and Cybernetics, Miyazaki, Japan, October 2018, pp. 1658--1663.
URL: https://ieeexplore.ieee.org/abstract/document/8616283
URL: https://ieeexplore.ieee.org/abstract/document/8616283
Group



Alumni




